The Diabetes Epidemic
In 2015, the International Diabetes Federation estimated that 415 million adults have diabetes worldwide, and projected this number to grow by 50 percent to 642 million by 2040.2 As many as 35 to 50 percent of all diabetics may have diabetic retinopathy.3 Of those, 10 percent may be at risk for visual loss, meaning that up to 25 million people could be at risk of significant visual impairment.4 Despite these dangers, however, a recent U.S. study noted that just 55 percent of patients with diabetes who were recommended for eye screening actually obtained a screening exam.5 This figure is likely even lower in less-developed countries. Thus, the global need for improved access and adherence to screening programs is immense.
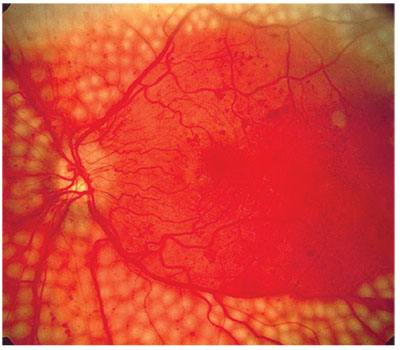 |
| A computer system with high sensitivity and specificity could weed out cases that don’t require treatment from those that do (above). |
The Project Begins
During a trip to India, a Google employee (Google has not made the employee’s identity public) was struck by the grave eye-care needs of the country’s underserved population. The employee came back to the Bay Area with a passion for using Google’s data-science capabilities to prevent vision loss—and the project was born. “The primary motivation for us is to improve access to low-cost, high-quality medical diagnostics, and to develop a technology that positively impacts everyone,” says Dr. Gulshan, a senior research scientist at Google.6 Over time, deep-learning technology has demonstrated real promise as a means to reduce vision loss.
To understand the project, though, it helps to understand machine learning and a subset of it known as deep learning. Recently, the terms “artificial intelligence” and “machine learning” have become increasingly popular, although they’re not synonymous. Artificial intelligence is a theoretical term referring to the ability of a machine to accomplish tasks that normally require human intelligence. Machine learning, on the other hand, refers to a computer’s ability to teach or improve itself via experience, without explicit programming for each improvement. Deep learning is a subsection within machine learning that focuses on using artificial neural networks to address highly abstract problems, like complex images.
The algorithm used in the Google study for automated diabetic retinopathy analysis is an example of deep learning. It’s an advanced artificial neural network loosely modeled after the human brain. An artificial neural network is a computing system made up of a number of simple, highly interconnected processing elements.1 The many nodes, or simple processors, within a neural network each perform simple calculations, which are weighted and summed to produce the final network output.
The Google system was first trained using hundreds of thousands of images labeled with a diagnosis by ophthalmologists. During the training phase, the system was initially presented with an image and it then made a guess as to what it might be. It then compared its answer to the ophthalmologists’ labeled answer and adjusted the weight it gave to each node, learning how to compute with the lowest possible diagnostic error. It did this with hundreds of thousands of images. (See Figure, above) The number of nodes is restricted so that the system can’t simply memorize the diagnosis for each image, but rather is forced to learn broad rules which are more likely to be generalizable to future, unseen images. “While it took immense computing power to train the algorithm, the eventual finished tool will be able to run on very basic computer hardware,” notes study author Dr. Peng, a product manager at Google.7
More important, the Google deep- learning neural network doesn’t include explicitly programmed feature recognition, which might look for retinal hemorrhages or cotton wool spots. Instead, the algorithm looks at every pixel of the photo and learns to recognize the severity of retinopathy using the full image. Currently, it’s not entirely known which specific aspects of an image the algorithm is actually using to find the correct diagnosis, but this is an area of very active research by the team. It’s interesting to consider that the algorithm may be using elements of the image that are different than those ophthalmologists use to arrive at the correct diagnosis.
When the Google team started the project, the initial task was to obtain a large library of fundus photos of diabetics for use in training the algorithm to recognize and grade diabetic retinopathy on color fundus images. For that, the Google team turned to existing large screening programs: 128,175 macula-centered fundus photographs were obtained from Eye Patient Archive Communication System, or EyePACS, in the United States and three eye hospitals in India (Aravind Eye Hospital, Sankara Nethralaya and Narayana Nethralaya). The images had 45-degree fields of view and more than half of them were non-mydriatic. Each of these images was then graded three to seven times by a group of 54 ophthalmologists, and nearly 10 percent of the images were randomly selected to be re-graded by the same physicians in order to assess intra-grader reliability. Images were assessed for the degree of diabetic retinopathy based on the International Clinical Diabetic Retinopathy scale of none, mild, moderate, severe or proliferative. Furthermore, visible hard exudates were used as a proxy for macular edema. This graded image set was then shown to the algorithm for training. Though the algorithm’s accuracy leveled off at about 60,000 images, nearly twice that number were used.
Following the training phase, the system was validated by testing its diagnoses relative to a reference standard of ophthalmologists’ assessments on tens of thousands of images it hadn’t seen before (known as “out-of-sample” images). For this validation testing, the investigators used two sets of out-of-sample images (EyePACS-1 set = 9,963 images, and Messidor-2 set = 1,748 images). Each of these nearly 11,000 images was graded by a minimum of seven board-certified ophthalmologists, and a majority opinion was taken as the Ground Truth. Ground Truth refers to the answer (or grade) taken as the “real” or correct answer, and to which the algorithm was compared.
In the two sets, when programmed for very high sensitivity, the algorithm achieved a sensitivity of 97.5 and 96.1 percent, and a specificity of 93.4 and 93.9 percent. Using an 8-percent prevalence of referable diabetic retinopathy in the population, these results yielded a negative predictive value (the probability that subjects who screen as negative truly don’t have the disease) of 99.6 to 99.8 percent. Needless to say, these results were impressive.
What Does It All Mean?
The opportunities for artificial intelligence in ophthalmology are broad. The introduction of this kind of technology into the real world may increase efficiency and reduce the cost of screening and diagnosis. It may also increase consistency, considering the variability between physician graders that was seen in the study.
In health-care systems with few resources, there are clear benefits to machine-based automated diagnosis: We can unburden eye-care providers and clinics that are stretched too thin. We can also provide screening for those who might not otherwise be able to obtain it, for low or no cost. The importance of maintaining high specificity in the presence of high sensitivity cannot be overstated. Maximizing sensitivity goes a long way toward not missing patients with disease, but sacrificing specificity to achieve this yields overdiagnosis of disease, causing overcrowding of clinics with patients who don’t need to be seen. Google’s advanced algorithm appears to perform well on both fronts.
In health-care settings with ample resources, there are also opportunities. First, it’s important to remember that there are large populations in the United States not being adequately screened for eye disease, especially diabetic retinopathy.5 This means that a new low-cost, highly efficient screening system may reach people who are currently not being screened for eye diseases:
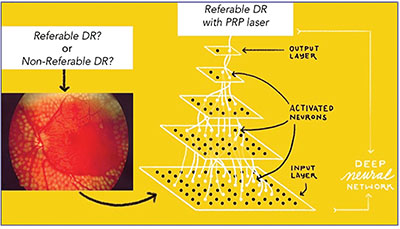 |
| Patterns are presented to the network via the “input layer,” which communicates to one or more “hidden layers” where the actual processing is done via a system of weighted connections. The hidden layers then link to an “output layer” where the result is given. |
Secondly, if the quality and breadth of the final system are sufficient, machine learning may be a diagnostic aid to eye-care professionals, improving the efficiency (and reducing the cost) of disease diagnosis and staging.
The Future
The future is bright for deep learning technologies in ophthalmology. With just a bit of imagination, we can envision a system in the future that diagnoses many different diseases and rules out any abnormalities, maybe even a multimodality total-eye diagnostic system. It’s likely that this kind of system would lower the cost of early-stage eye care and could also reduce the burden and cost of eye disease overall.
For ophthalmologists and optometrists specifically, comprehensive automated diagnostic technology no doubt will cause changes to their fields, and the complexity of those changes is difficult to predict. For instance, these types of technologies may require ophthalmologists to focus more on management and patient education, and less on diagnosis. It’s too early to tell at this point.
It’s easy to let our imaginations run wild with this type of new technology, however. Right now, Google has shown it can diagnose and grade one disease in a study setting. We still have yet to see how this technology performs in the real world. Also, there are many diseases left to work on, not to mention the all-important task of catching life-threatening conditions in screening images, such as ocular melanoma. REVIEW
Dr. Karth is a vitreoretinal specialist at Oregon Eye Consultants and an adjunct assistant clinical professor at Stanford University. He can be reached at peterkarth@gmail.com; PeterKarthMD on Twitter, Facebook and LinkedIn. Dr. Rahimy is a vitreoretinal specialist at the Palo Alto Medical Foundation, and may be reached at erahimy@gmail.com; SFretina on Twitter. Both authors are physician research consultants for Google.
1. Gulshan V, Peng L, Coram M, et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016;316;22:2402-2410.
2. IDF Diabetes Atlas, 2016. International Diabetes Foundation.
3. Zheng Y, He M, Congdon N. The worldwide epidemic of diabetic retinopathy. Indian Journal of Ophthalmology 2012;60:5:428-.
4. The Diabetic Retinopathy Study Research Group. Photocoagulation treatment of proliferative diabetic retinopathy. Clinical application of diabetic retinopathy study (DRS) findings. (DRS report no. 8). Ophthalmology 1981;88:7:583-600.
5. Yang Lu, Serpas L, Genter P, et al. Disparities in diabetic retinopathy screening rates within minority populations: Differences in reported screening rates among African American and Hispanic patients. Diabetes Care 2016;39:e31-e32.
6. Personal communication.
7. Personal communication.


